Kubernetes_Monitoring
Prerequisites must be installed and configured.
All action done on kubernetes master server.
Clone or copy YAML script from below git repo.
git clone https://github.com/bibinwilson/kubernetes-prometheus
Create a monitoring Namespace
[root@kmaster ~]# kubectl create namespace monitoring
You need to assign cluster reader permission to this namespace so that Prometheus can fetch the metrics from kubernetes API’s.
[root@kmaster ~]# kubectl create -f clusterRole.yaml
Create a Config Map
We should create a config map with all the prometheus scrape config and alerting rules,
which will be mounted to the Prometheus container in /etc/prometheus as prometheus.yaml and prometheus.rules files.
The prometheus.yaml contains all the configuration to dynamically discover pods and services running in the kubernetes cluster.
prometheus.rules will contain all the alert rules for sending alerts to alert manager.
[root@kmaster ~]# kubectl create -f config-map.yaml -n monitoring
Create a Prometheus Deployment
[root@kmaster ~]# kubectl create -f prometheus-deployment.yaml --namespace=monitoring
[root@kmaster ~]# kubectl get deployments --namespace=monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus-deployment 1/1 1 1 16m
Get the Prometheus pod name.
[root@kmaster ~]# kubectl get pods --namespace=monitoring
NAME READY STATUS RESTARTS AGE
prometheus-deployment-fd6676489-wmn6w 1/1 Running 0 18m
Exposing Prometheus as a Service so we can connect prometheus with Grafana.
To access the Prometheus dashboard over a IP or a DNS name, you need to expose it as kubernetes service.
Note: If you are on AWS or Google Cloud, You can use Loadbalancer type, which will create a load balancer and points it to the service.
[root@kmaster ~]# kubectl create -f prometheus-service.yaml --namespace=monitoring
[root@kmaster ~]# kubectl get services --namespace=monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-service NodePort 10.103.247.50 <none> 8080:30000/TCP 24s
Once created, you can access the Prometheus dashboard using any Kubernetes node IP on port 30000. If you are on the cloud, make sure you have the right firewall rules for accessing the apps.
In my example "Grafana" deploy on separate server.
Add repo to install "Grafana"
[root@feenixdv yum.repos.d]# cat grafana.repo
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
[root@feenixdv yum.repos.d]# yum install grafana
[root@feenixdv yum.repos.d]# yum list installed grafana
Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
Installed Packages
grafana.x86_64 6.0.1-1 @grafana
[root@feenixdv yum.repos.d]# systemctl restart grafana-server.service
[root@feenixdv yum.repos.d]# systemctl status grafana-server
? grafana-server.service - Grafana instance
Loaded: loaded (/usr/lib/systemd/system/grafana-server.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2019-03-14 20:54:34 PDT; 5h 35min ago
Now Grafana access on http://IP:3000. Default login is "admin/admin".
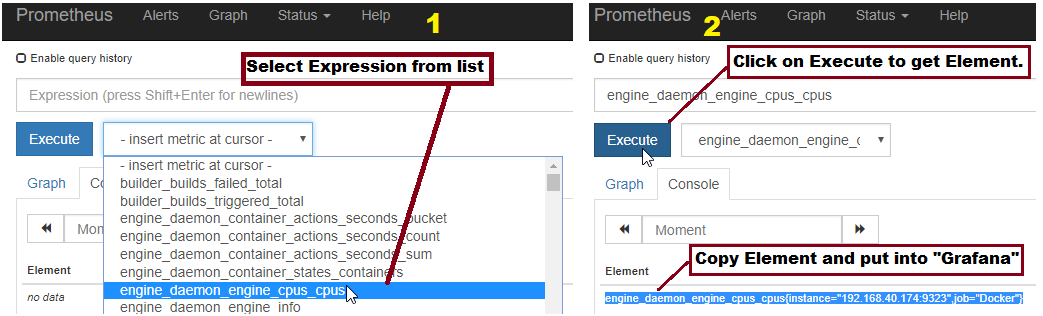
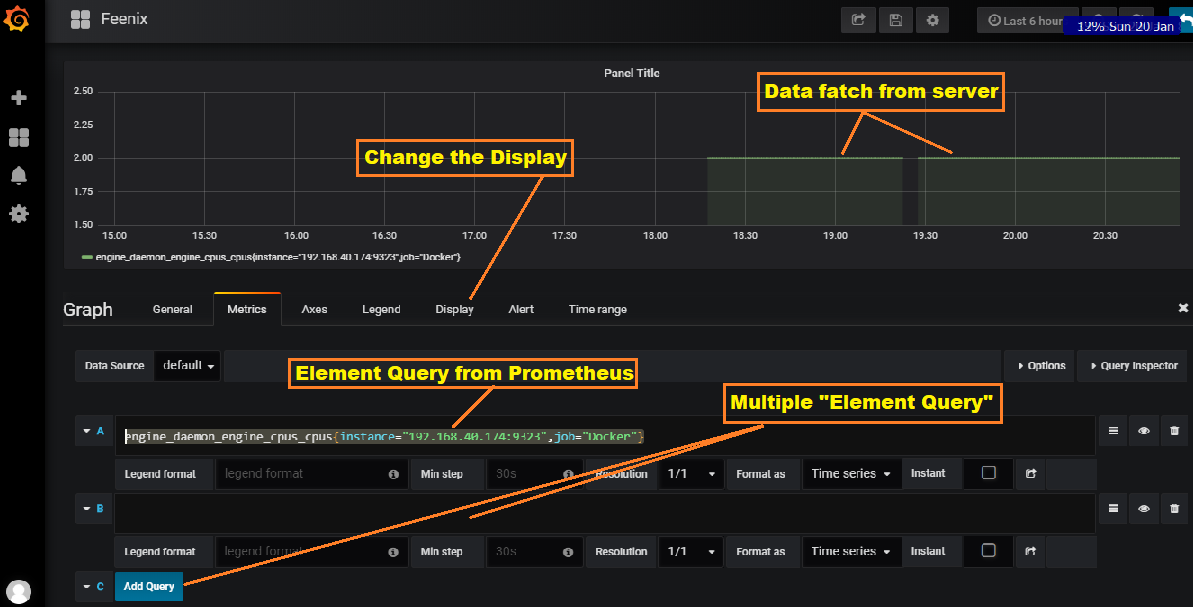
Now create connection with Prometheus and create graph.

Now craete graph.
Example:-
Variables:-
Name:- Node Query:- label_values(kubernetes_io_hostname)
Name:- Deployment Query:- label_values(deployment)
Name:- Statefulset Query:- label_values(statefulset)
Name:- Daemonset Query:- label_values(daemonset)
some Graph query example:-
Name:- 10 CPU hungry pods
Visualization:- Graph
Query:- sort_desc(topk(10, sum by (pod_name)( rate(container_cpu_usage_seconds_total{pod_name!=""}[1m] ) )))

Name:-10 memory hungry pods
Visualization:-Graph
Query:-sort_desc(topk(10, sum(container_memory_usage_bytes{pod_name!=""}) by (pod_name)))

Name:-Deployment CPU usage
Visualization:-Singlestat
Query:-sum (rate (container_cpu_usage_seconds_total{pod_name=~"^$Deployment$Statefulset$Daemonset.*$", kubernetes_io_hostname=~"^$Node$"}[2m])) / sum (machine_cpu_cores{kubernetes_io_hostname=~"^$Node$"}) * 100

Name:-CPU usage
Visualization:-Graph
Query:-sum (rate (container_cpu_usage_seconds_total{image!="",name=~"^k8s_.*",io_kubernetes_container_name!="POD",pod_name=~"^$Deployment$Statefulset$Daemonset.*$",kubernetes_io_hostname=~"^$Node$"}[1m])) by (pod_name,kubernetes_io_hostname)
sum (kube_pod_container_resource_requests_cpu_cores{pod=~"^$Deployment$Statefulset$Daemonset.*$",node=~"^$Node$"}) by (pod,node)
sum ((kube_node_status_allocatable_cpu_cores{node=~"^$Node$"})) by (node)

Name:-Memory usage
Visualization:-Graph
Query:-sum (container_memory_working_set_bytes{id!="/",pod_name=~"^$Deployment$Statefulset$Daemonset.*$",kubernetes_io_hostname=~"^$Node$"}) by (pod_name,kubernetes_io_hostname)
sum ((kube_pod_container_resource_requests_memory_bytes{pod=~"^$Deployment$Statefulset$Daemonset.*$",node=~"^$Node$"})) by (pod,node)
sum ((kube_node_status_allocatable_memory_bytes{node=~"^$Node$"})) by (node)

Name:-All processes network I/O
Visualization:-Graph
Query:-sum (rate (container_network_receive_bytes_total{id!="/",pod_name=~"^$Deployment$Statefulset$Daemonset.*$",kubernetes_io_hostname=~"^$Node$"}[1m])) by (pod_name, kubernetes_io_hostname)
– sum( rate (container_network_transmit_bytes_total{id!="/",pod_name=~"^$Deployment$Statefulset$Daemonset.*$",kubernetes_io_hostname=~"^$Node$"}[1m])) by (pod_name, kubernetes_io_hostname)